
TinyML - IA EMBARQUEE
Développement d'un modèle TinyML via Edge Impulse pour la classification de mouvements (horizontal vs vertical) en utilisant l'accéléromètre d'un smartphone.
Contributeurs
Boris TAKOU KENNE
Compétences
TinyML
Edge Impulse
Embedded AI
Publié
08 Mars 2026
Liens importants
GitHubContexte du projet
Ce projet montre comment construire un Tinymodel en utilisant la plateforme edge impulse pour le développement d'un modèle d'apprentissage automatique sur dispositifs embarqués. C'est le premier d'une série d'expérimentations sur le TinyML.
TinyML désigne l'implémentation de modèles de Machine Learning sur des dispositifs à faible consommation d'énergie, permettant l'exécution de tâches d'IA directement sur des microcontrôleurs.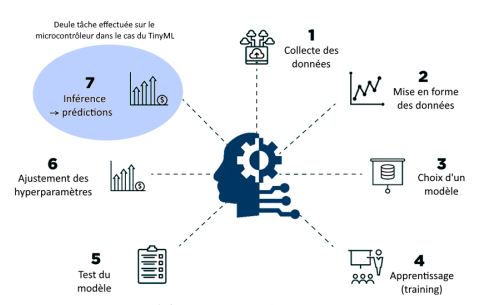
TinyML désigne l'implémentation de modèles de Machine Learning sur des dispositifs à faible consommation d'énergie, permettant l'exécution de tâches d'IA directement sur des microcontrôleurs.
| Avantages | Inconvénients |
|---|---|
| Faible consommation d'énergie | Capacité limitée : Ressources mémoires et puissance de calcul restreintes. |
| Latence réduite : Calculs locaux sans cloud. | Performances moindres : Nécessité de simplifier les modèles. |
| Portabilité : Intégration dans de petits objets non connectés. | Domaine émergent : Outils moins matures que l'IA traditionnelle. |
Étapes du projet
1
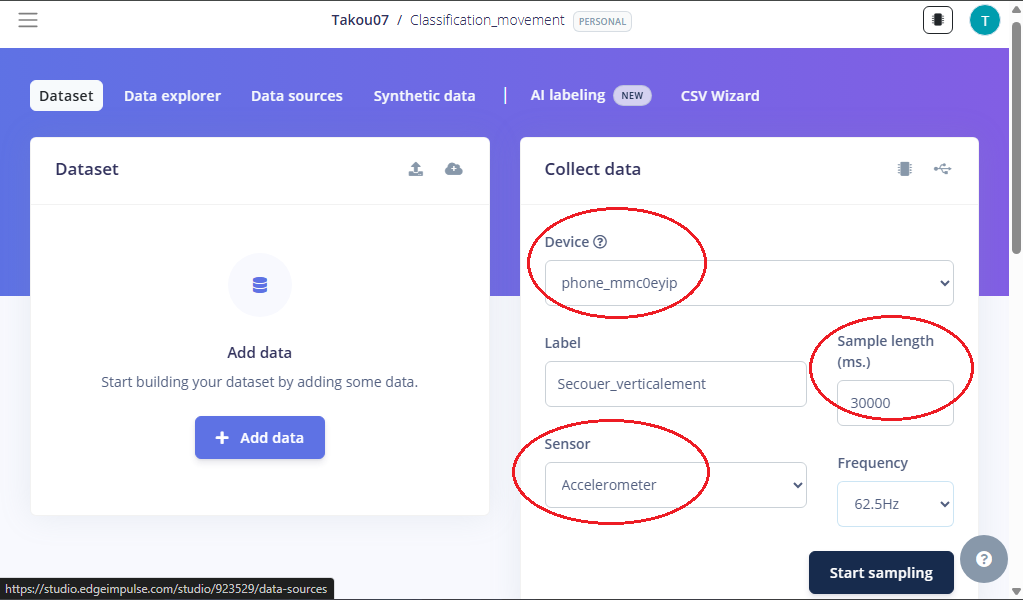
Acquisition des données avec ton Smartphone
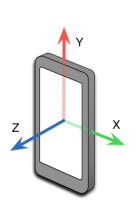
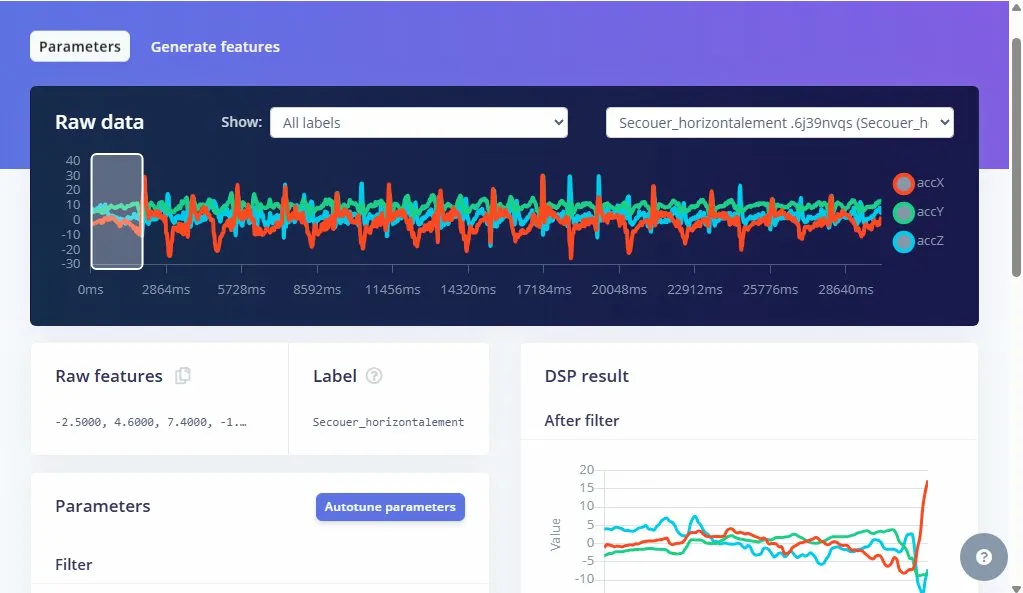
TerminéNos smartphones possèdent une centrale inertielle (IMU - Inertial Measurement Unit) qui regroupe plusieurs capteurs : l'accéléromètre (accélérations linéaires), le gyroscope (vitesse de rotation) et le magnétomètre (champ magnétique). Dans ce projet, le capteur principal est l'accéléromètre, qui mesure l'accélération sur 3 axes (X, Y, Z) en m/s² ou en g.
Comme nous allons ici résoudre un problème de classification associé à des mouvements du smartphone, nous créons deux classes distinctes : Secouer verticalement et Secouer horizontalement.
Pour obtenir un modèle performant, l'acquisition d'un volume de données suffisant (le dataset) est cruciale. Nous effectuons 4 acquisitions de 30 secondes pour chaque classe.
L'acquisition du signal démarre automatiquement sur le smartphone. À la fin, nous obtenons des courbes de l'évolution temporelle des accélérations mesurées suivant les trois directions.
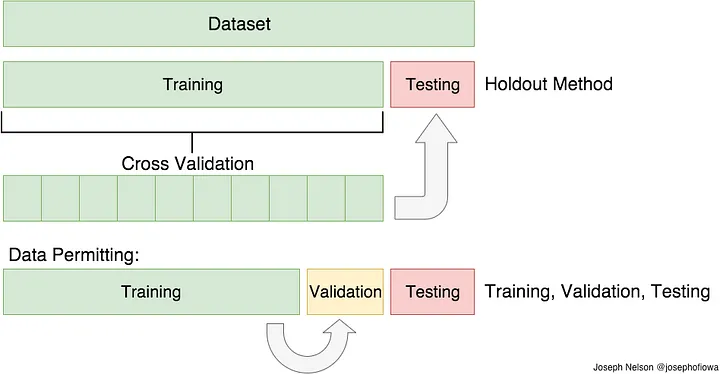
Après avoir acquis toutes les données, nous les divisons en trois ensembles : le Training Set (75%) pour entraîner l'IA, le Validation Set pour affiner les paramètres de l'estimateur, et le Testing Set (25%) pour évaluer les prédictions finales sur des données jamais vues.
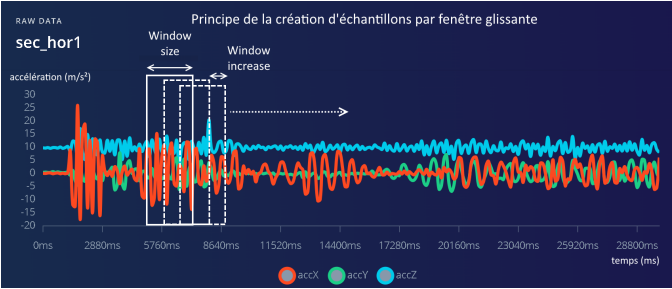
Afin de transformer le signal continu en données exploitables, nous utilisons la méthode de la fenêtre glissante (sliding window). Ce principe consiste à découper le signal en segments de taille fixe. Si le pas de déplacement est inférieur à la taille de la fenêtre, le chevauchement permet de générer davantage d'échantillons et d'éviter de manquer un geste entre deux découpes.
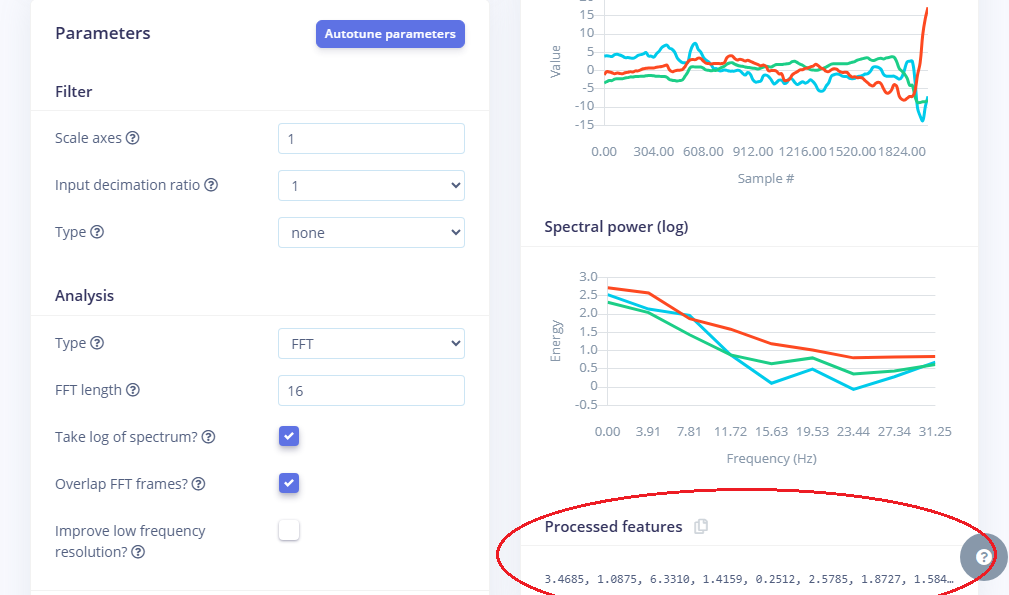
Avant l'entraînement, nous extrayons des caractéristiques spectrale (FFT). L'analyse du spectre permet d'identifier les fréquences dominantes. Par exemple :
- Rotation : Énergie marquée entre 2-4 Hz avec un pic unique.
- Marche : Énergie à 1-2 Hz, pic régulier cadencé.
- Chute : Signal large bande (Énergie sur toutes les fréquences).
- Repos : Énergie quasi nulle.
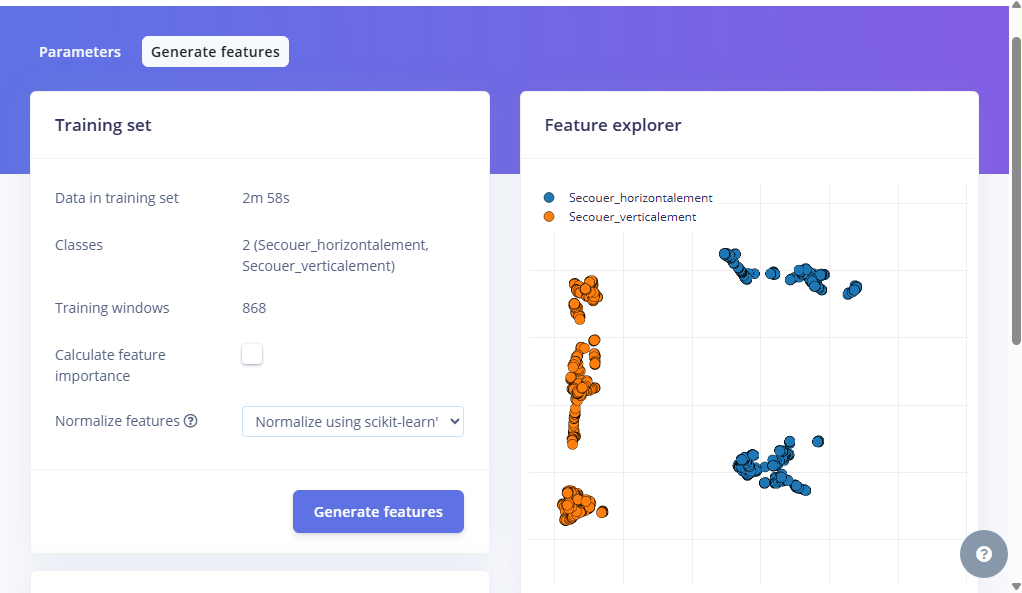
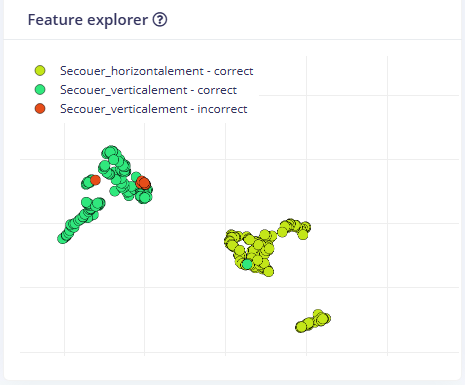
Ces attributs (features) extraits sont alors visualisés sous forme de clusters de couleurs differentes dans le Feature Explorer. Si les points forment des groupes bien séparés, cela signifie que nos caractéristiques permettent de distinguer efficacement les mouvements.
Comme nous allons ici résoudre un problème de classification associé à des mouvements du smartphone, nous créons deux classes distinctes : Secouer verticalement et Secouer horizontalement.
Pour obtenir un modèle performant, l'acquisition d'un volume de données suffisant (le dataset) est cruciale. Nous effectuons 4 acquisitions de 30 secondes pour chaque classe.
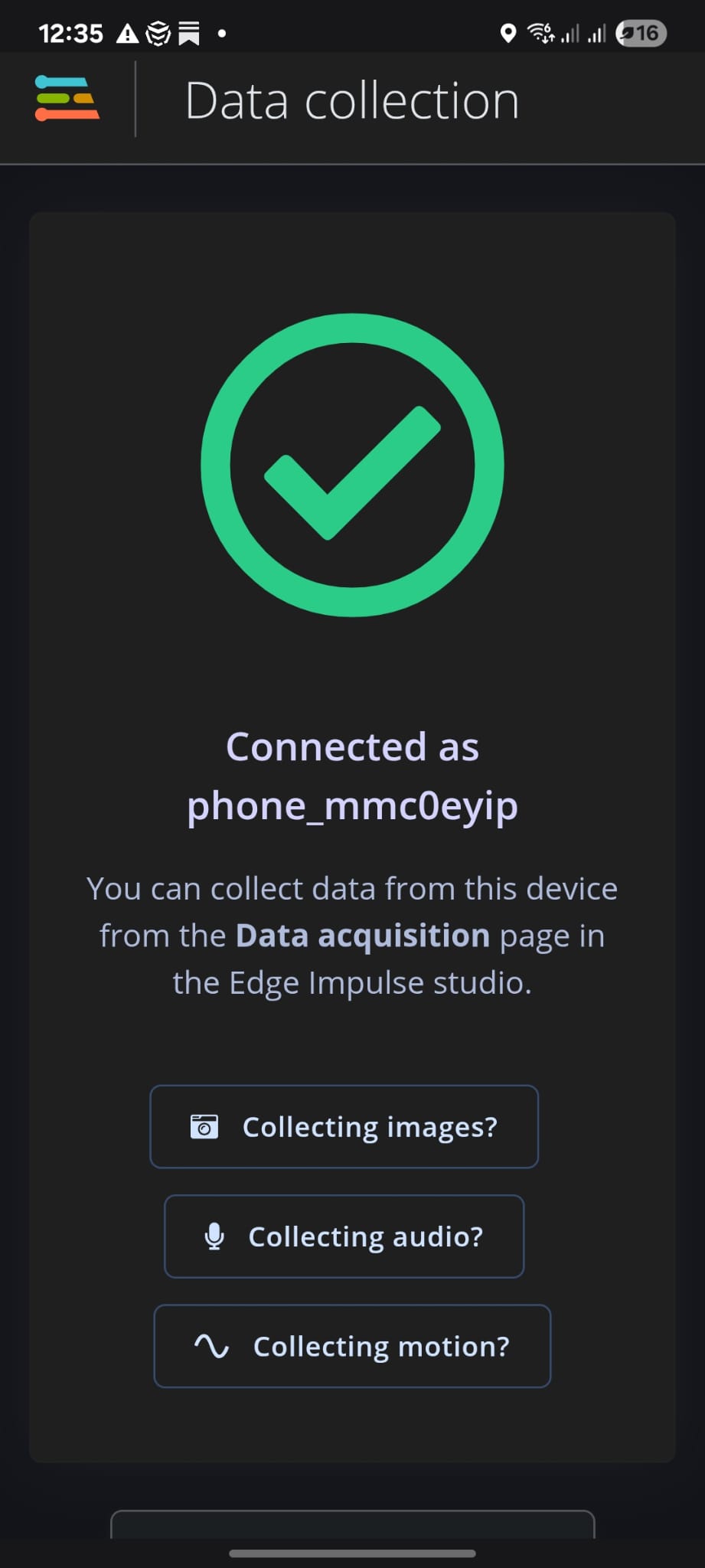
L'acquisition du signal démarre automatiquement sur le smartphone. À la fin, nous obtenons des courbes de l'évolution temporelle des accélérations mesurées suivant les trois directions.
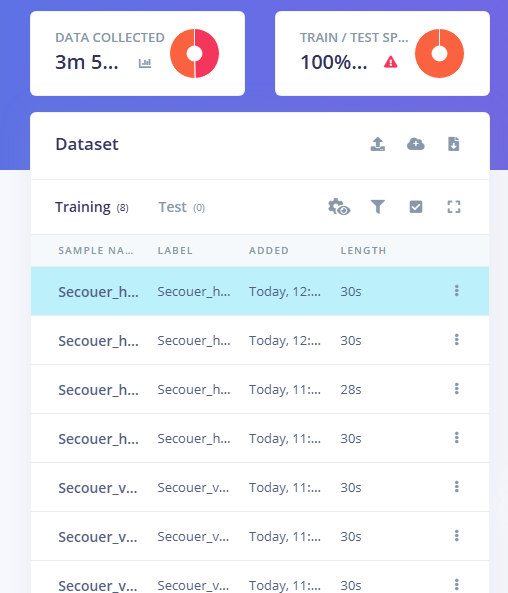
Après avoir acquis toutes les données, nous les divisons en trois ensembles : le Training Set (75%) pour entraîner l'IA, le Validation Set pour affiner les paramètres de l'estimateur, et le Testing Set (25%) pour évaluer les prédictions finales sur des données jamais vues.
Afin de transformer le signal continu en données exploitables, nous utilisons la méthode de la fenêtre glissante (sliding window). Ce principe consiste à découper le signal en segments de taille fixe. Si le pas de déplacement est inférieur à la taille de la fenêtre, le chevauchement permet de générer davantage d'échantillons et d'éviter de manquer un geste entre deux découpes.
Avant l'entraînement, nous extrayons des caractéristiques spectrale (FFT). L'analyse du spectre permet d'identifier les fréquences dominantes. Par exemple :
- Rotation : Énergie marquée entre 2-4 Hz avec un pic unique.
- Marche : Énergie à 1-2 Hz, pic régulier cadencé.
- Chute : Signal large bande (Énergie sur toutes les fréquences).
- Repos : Énergie quasi nulle.
Ces attributs (features) extraits sont alors visualisés sous forme de clusters de couleurs differentes dans le Feature Explorer. Si les points forment des groupes bien séparés, cela signifie que nos caractéristiques permettent de distinguer efficacement les mouvements.
2
Choix du modèle
TerminéNous configurons l'entraînement avec 30 époques (le modèle verra l'ensemble des données 30 fois) et un learning rate de 0.0005. À chaque cycle, il ajuste ses poids pour minimiser l'erreur de classification.
L'architecture du réseau de neurones comprend une couche d'entrée, 2 couches cachées respectivement de 20 neurones et 10 neurones chacune pour extraire les patterns non linéaires, et une couche de sortie gérant la classification finale.
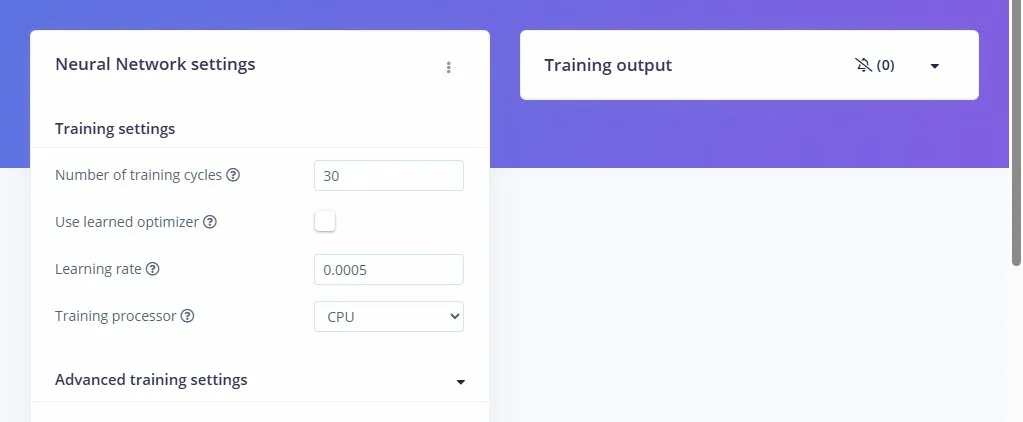
L'architecture du réseau de neurones comprend une couche d'entrée, 2 couches cachées respectivement de 20 neurones et 10 neurones chacune pour extraire les patterns non linéaires, et une couche de sortie gérant la classification finale.
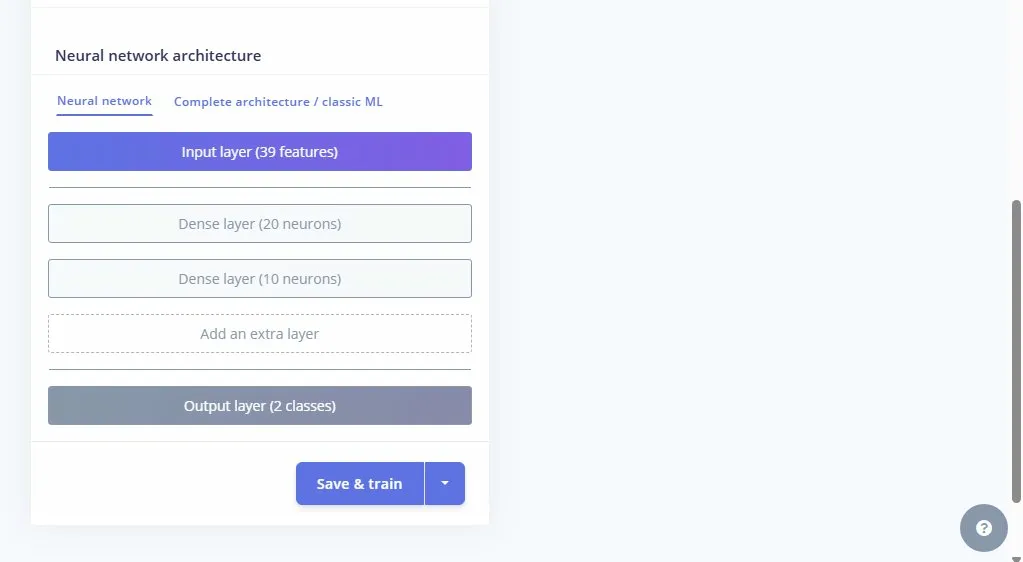
3
Phase d'apprentissage
TerminéC'est à cette étape que Edge Impulse utilise entre autres un algorithme de descente de gradient pour ajuster les poids et les biais associés à chaque neurone artificiel.
Le modèle a ici une précision (accuracy) de 100%. Cela signifie que 100% des échantillons des données d'entrainement ont vu leur classe de sortie prédite correctement.
Pour aller plus dans le détail, on peut observer la matrice de confusion :
- En colonnes, les classes prédites par l'algorithme.
- En lignes, les classes connues car étiquetées dans les données d'entrainement.
Le Data explorer nous permet de retrouver les échantillons pour lesquels la prédiction a été mauvaise. Ici, on peut voir qu'aucun échantillon n'a vu sa classe mal prédite.
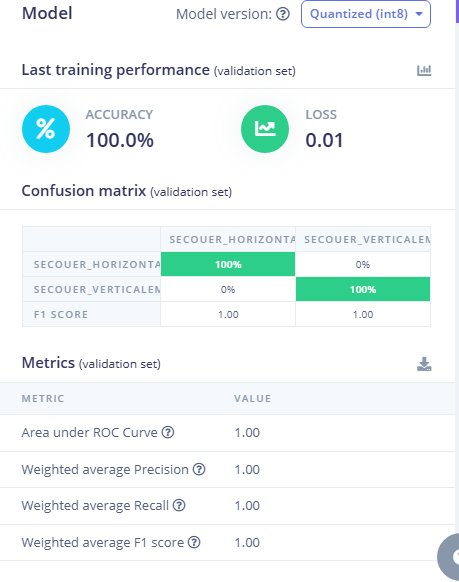
Le modèle a ici une précision (accuracy) de 100%. Cela signifie que 100% des échantillons des données d'entrainement ont vu leur classe de sortie prédite correctement.
Pour aller plus dans le détail, on peut observer la matrice de confusion :
- En colonnes, les classes prédites par l'algorithme.
- En lignes, les classes connues car étiquetées dans les données d'entrainement.
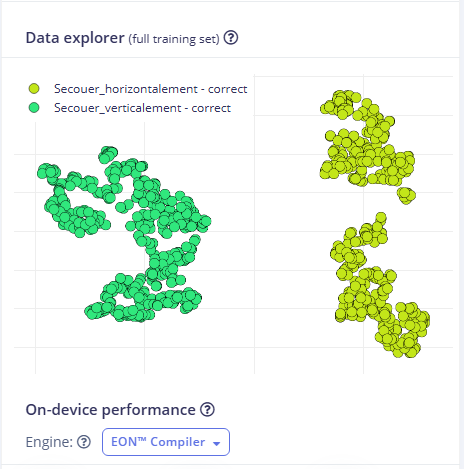
Le Data explorer nous permet de retrouver les échantillons pour lesquels la prédiction a été mauvaise. Ici, on peut voir qu'aucun échantillon n'a vu sa classe mal prédite.
4
Test du modèle
TerminéOn obtient un récapitulatif de performances similaire au précédent. Assez logiquement, les performances sont un peu moins satisfaisantes que sur le set de données d'entrainement (on rappelle que l'algorithme n'avait "jamais vu" les données de test).
Dans l'exemple ci-contre, la précision obtenue, supérieure à 97.60% est satisfaisante.
Ici le Feature explorer nous permet de retrouver les échantillons pour lesquels la prédiction a été mauvaise. Ci-contre, on peut voir que 6 échantillons ont vu leur classe mal prédite.
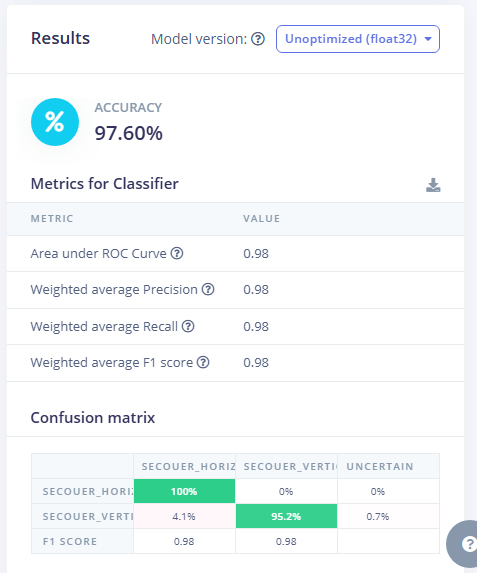
Dans l'exemple ci-contre, la précision obtenue, supérieure à 97.60% est satisfaisante.
Ici le Feature explorer nous permet de retrouver les échantillons pour lesquels la prédiction a été mauvaise. Ci-contre, on peut voir que 6 échantillons ont vu leur classe mal prédite.
5
Inference/Predictions
TerminéOn entre ici dans la phase d'utilisation (inférence) de l'algorithme d'IA qui a été précédemment entraîné et testé.
Première possibilité avec Edge Impulse : "Live Classification" – adapté au test rapide du modèle. Ici j'ai effectué un mouvement vertical durant l'inference et on peut constater que le modèle à prédit plus de mouvement vertical que de mouvement horizontal
À la fin de l'acquisition, la mesure apparaît à l'écran de l'ordinateur. On retrouve le découpage en plusieurs échantillons avec la méthode de la fenêtre glissante, ce qui amène plusieurs échantillons pour une seule mesure. Pour chaque échantillon, l'algorithme effectue une prédiction d'appartenance à une des classes. Cette prédiction est caractérisée par une probabilité (entre 0 et 1) d'appartenance à chaque classe.
Première possibilité avec Edge Impulse : "Live Classification" – adapté au test rapide du modèle. Ici j'ai effectué un mouvement vertical durant l'inference et on peut constater que le modèle à prédit plus de mouvement vertical que de mouvement horizontal
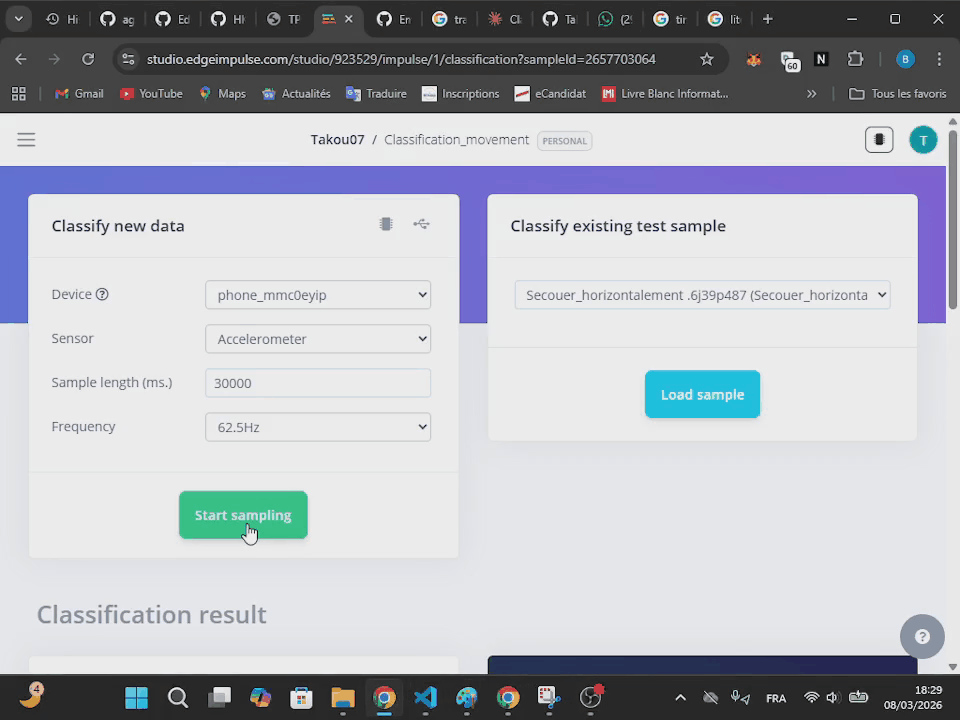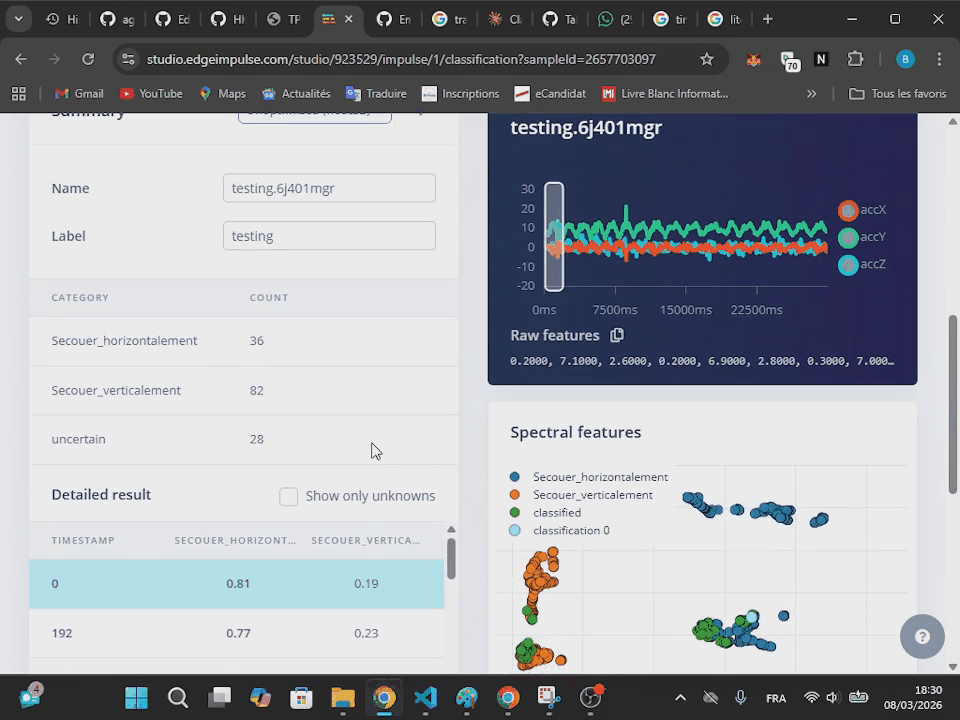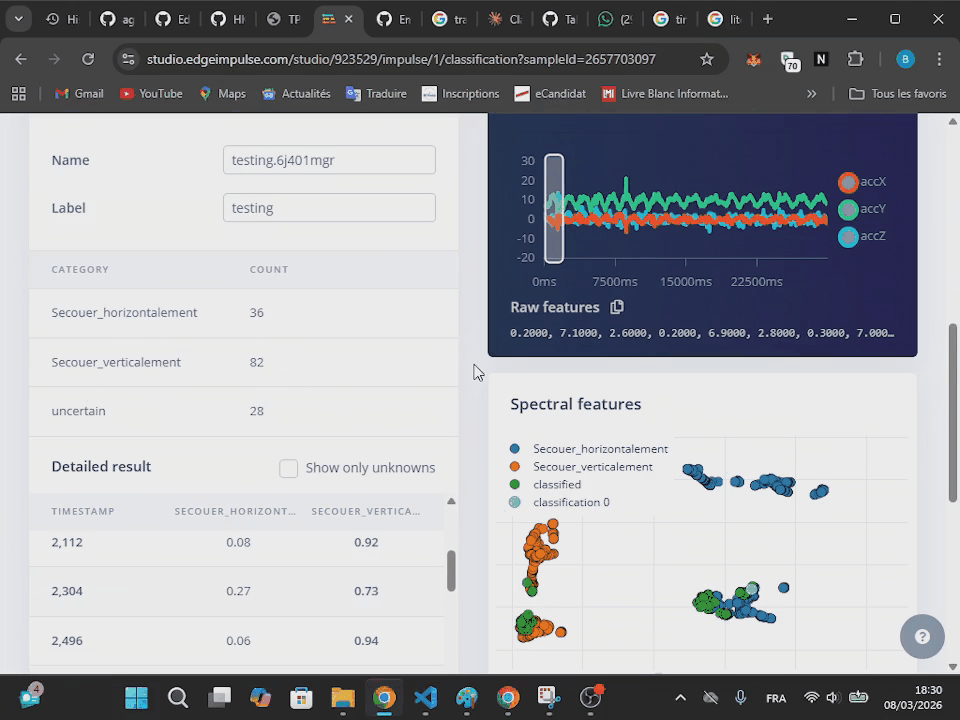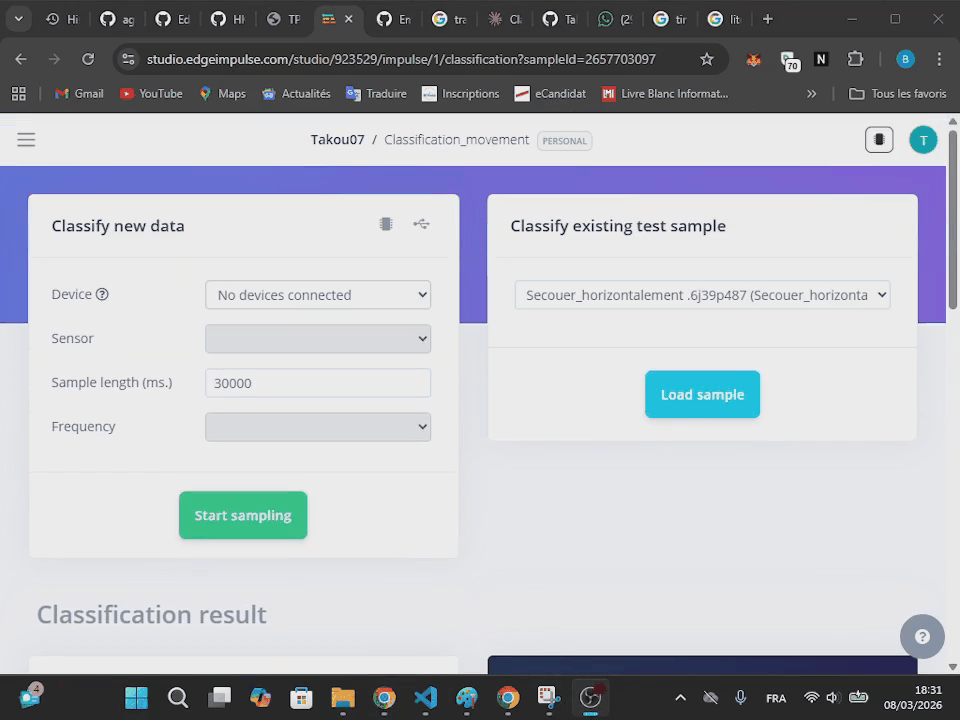
À la fin de l'acquisition, la mesure apparaît à l'écran de l'ordinateur. On retrouve le découpage en plusieurs échantillons avec la méthode de la fenêtre glissante, ce qui amène plusieurs échantillons pour une seule mesure. Pour chaque échantillon, l'algorithme effectue une prédiction d'appartenance à une des classes. Cette prédiction est caractérisée par une probabilité (entre 0 et 1) d'appartenance à chaque classe.
6
A faire plus tard
À faireDéployer mon modèle d'IA créé dans mon téléphone et l'utiliser sous forme de WebApp pour détecter les mouvements.
