RAG Framework From Scratch
Développement d'un framework RAG (Retrieval-Augmented Generation) complet à partir de zéro, permettant d'interroger des documents personnels avec une précision accrue grâce à l'intégration de bases de données vectorielles et de modèles de langage.
Contributeurs
Boris TAKOU KENNE
Compétences
LLM
Python
Vector DB
RAG
LangChain
Publié
Mars 2026
Liens importants
GitHubContexte du projet
Les LLMs sont entraînés sur de vastes volumes de données, mais ces données restent statiques.
Cela limite leur capacité à raisonner sur des informations récentes, spécifiques ou propriétaires.
Une solution consiste à faire du fine-tuning, mais cette approche est souvent coûteuse, longue à mettre en place et difficile à maintenir.
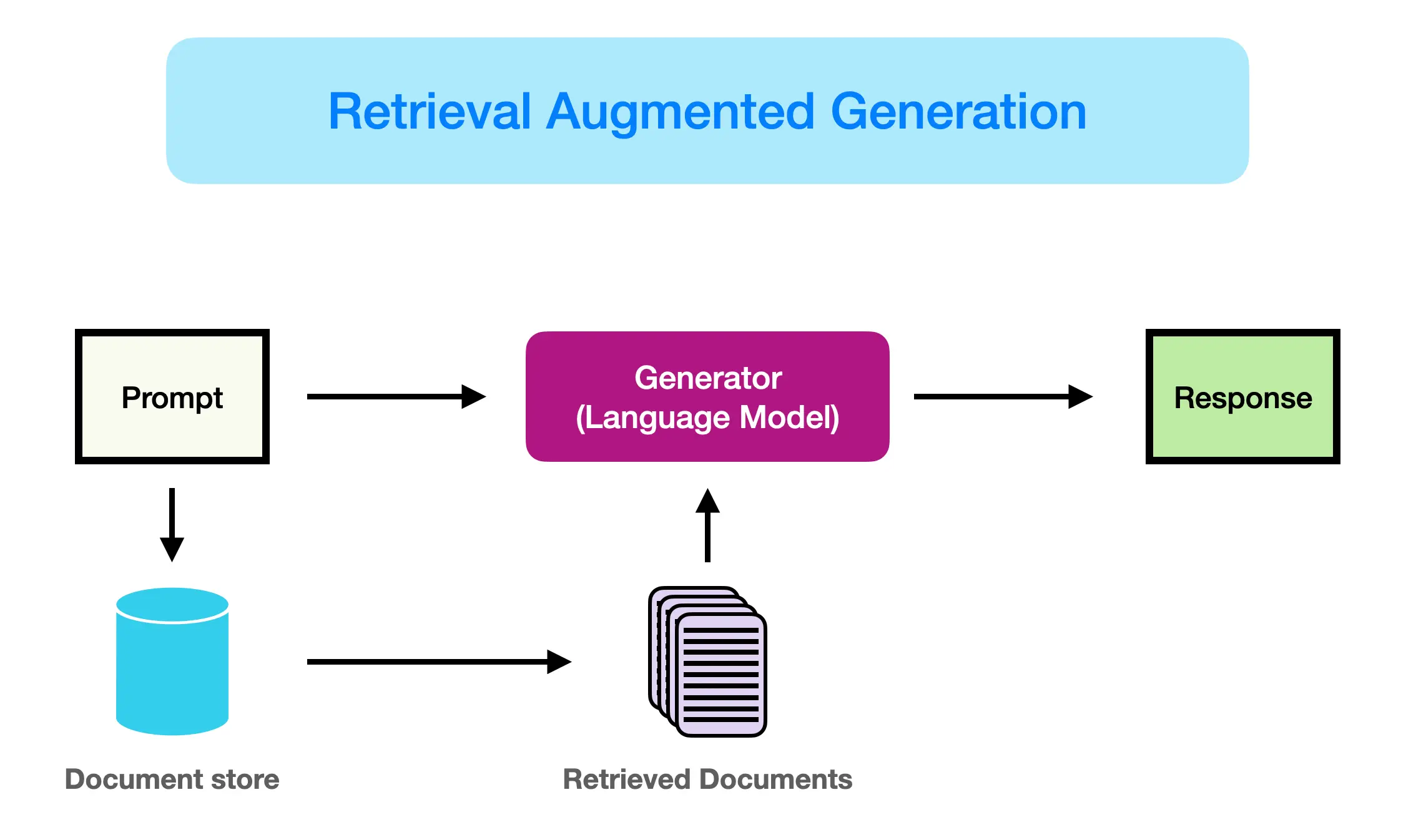
C’est ici qu’intervient le RAG (Retrieval-Augmented Generation).
Le RAG est un mécanisme qui permet d’étendre la base de connaissances d’un LLM en récupérant dynamiquement des informations depuis vos propres données (documents, bases internes, PDFs, etc.) pour enrichir la génération de réponse.
Dans ce projet, j’utilise LangChain, un framework open-source conçu pour construire des applications basées sur des LLMs et orchestrer des pipelines intelligents (chargement de documents, indexation, recherche sémantique, génération).
À travers ce projet, je compte approfondir trois axes principaux :
Cela limite leur capacité à raisonner sur des informations récentes, spécifiques ou propriétaires.
Une solution consiste à faire du fine-tuning, mais cette approche est souvent coûteuse, longue à mettre en place et difficile à maintenir.
C’est ici qu’intervient le RAG (Retrieval-Augmented Generation).
Le RAG est un mécanisme qui permet d’étendre la base de connaissances d’un LLM en récupérant dynamiquement des informations depuis vos propres données (documents, bases internes, PDFs, etc.) pour enrichir la génération de réponse.
Dans ce projet, j’utilise LangChain, un framework open-source conçu pour construire des applications basées sur des LLMs et orchestrer des pipelines intelligents (chargement de documents, indexation, recherche sémantique, génération).
À travers ce projet, je compte approfondir trois axes principaux :
📚 Document Indexing – structurer et vectoriser les documents pour les rendre exploitables
🔎 Semantic Search – récupérer les informations les plus pertinentes via des embeddings
🧠 LLM Generation – générer des réponses contextualisées et fiables
Étapes du projet
1
Charger les documents (Document Loading)
En coursRécupération des données pour les transformer en transformer tes données en objets Document
2
Découper les documents (Text Splitting)
À faireUn LLM ne digère pas 200 pages d’un coup donc découpe en petits chunks intelligents
3
Transformer en embeddings
À faireChaque chunk devient un vecteur numérique.
4
Stocker dans une base vectorielle
À faireOn range ces vecteurs dans une Vector Database comme ChromaDB, FAISS etc.
5
Retrieval (Recherche sémantique)
À faireOn transforme la question en embedding puis on cherche les vecteurs les plus proches enfin on récupère les chunks correspondants
6
Augmentation du prompt (Augmented Prompt)
À faireOn construit un prompt structuré pour enrichir la requête utilisateur avec les informations pertinentes.
7
Génération avec le LLM
À faireOn envoie ce prompt enrichi au modèle pour générer des réponses précises et sourcées en se basant sur les documents récupérés.
